Downloading public comments with a simple-to-use Python wrapper for the Regulations.gov API
22 Jul 2021 | Will JobsThe Python Wrapper: https://github.com/willjobs/regulations-public-comments
TL;DR: I created a Python wrapper for v4 of the Regulations.gov API, greatly simplifying the process of downloading public comments from Regulations.gov. You can use it at the command-line (without using any Python) to download all public comments on a given docket or docket, or use a little bit of Python to make a customized query (e.g., to download all comments on any EPA regulations in the past month). This may be the first publicly available wrapper to simplify use of version 4 of the Regulations.gov API.
Background
In the U.S., when federal agencies propose new regulations they are required to go through a formal review process. Typically, this includes a Notice of Proposed Rulemaking (NPRM), a public comment period, response to public comments, and Final Rule (see this, this and this). Public comments allow individuals and organizations to provide additional context, supporting information, and opinion about a proposed regulation (or removal thereof), though they are not treated as “votes” for or against a regulation.
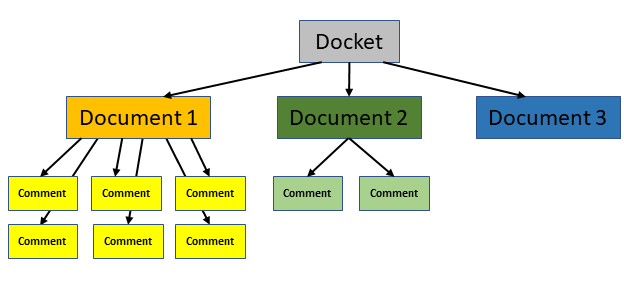
The structure of the data is as follows: all materials related to a given proposal regulation are contained within a docket. Each docket may contain one or more documents of various types (Notice, Proposed Rule, Rule, Supporting & Related Material, and Other), and the public may post comments about any document. Comments are associated with a document, not the docket.
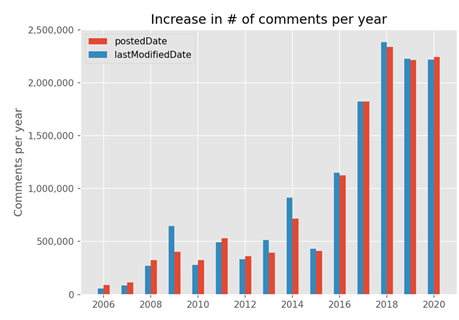
In 2003 the public comment process was made available electronically for the first time, and this led to a large spike in engagement.
The web interface allows users to search for dockets, documents, and comments, using search terms and filtering by things like agency, document type, posted date, and comment due dates. Searches for dockets can be filtered by a variety of other criteria as well.
The official API
In 2012 version 1.0 of a public API was created that allowed users to programmatically download comments from Regulations.gov (see the v1 documentation). Since then there have been several updates, and v4 of the API was released in September 2020. This latest version of the API added the capability for users to upload comments as well.
The API is very well-documented, with examples and clear specifications of parameters and responses. Nonetheless, there are some gotchas. For example, filtering by postedDate uses yyyy-mm-dd format, but filtering by lastModifiedDate uses yyyy-mm-dd hh24:mi:ss format. In addition, the lastModifiedDate filter uses the Eastern time zone, but the values returned in the response are in UTC, which can create a mismatch if you’re unaware and trying to paginate over multiple requests. Another example: when you’re trying to filter to comments for a specific document, you have to use the document’s objectId (an internal identifier returned by the API), not its documentId.
The pagination mechanism can also be tricky: you’re allowed up to 250 “items” (comments, documents, or dockets) per “page” (one request), and a query can access up to 20 of these pages for a total of 5,000 items per query. However, what if you’re querying (for example) all comments on EPA-related regulations in the past two years? The API would limit you to 5,000 items even though the number of comments would surely be larger than that (in this case, over 80,000). The way to handle this, as described in the documentation’s examples, is to:
- Construct your query as usual, sorting by
lastModifiedDate. - After the first page, each subsequent request should set
page[num]equal to the current page number. - On the last (20th) page, record the last item’s
lastModifiedDate. - Repeat steps 1-3, now adding a filter so that
lastModifiedDateis greater than or equal to the recordedlastModifiedDatefrom step 3. You have to set the date and time greater than or equal to because there can be comments posted at the exact same time (e.g., if they were uploaded in bulk or modified by system staff). However, this ensures that you will get duplicates, so you have to handle them on your own.
Finally, an API key (which you can request on the API documentation page) is limited to no more than 1,000 requests per hour. The Python wrapper handles this restriction by detecting the request error and automatically polling every 20 minutes until the API key’s limits are reset (occasionally the requests are reset sooner than the full 60 minutes), at which point requests are continued.
1,000 requests per hour may sound like a lot, but it turns out that, in order to get the text of a given comment, you have to access it individually. The description above about getting 250 items at a time only gets you some “header” information for each item, when what you’re most likely interested in is the “details” information. To understand this better, at the very bottom of the API documentation there is a Schemas section which lists all the data attributes returned by a given item. The “Comment” item is what is returned by the pagination process I described above, and it includes only agencyId, documentType, highlightedContent, lastModifiedDate, objectId, postedDate, title, and withdrawn. The actual text of the comment exists in the “CommentDetail” item of the schema, in the comment attribute, which is accessed one at a time, by commentId.
The Python Wrapper
My work began as a project for a class in NLP during my master’s degree, and as my codebase took shape, I realized that the lessons I’d learned from using the API might be useful to other people. Before I started the project, I spent a good amount of time searching GitHub and Google to see if I could build off someone else’s work, but there did not seem to be an existing wrapper for v4 of the API. I found a repo by Sunlight Labs (a now defunct organization), however their code was last updated in 2015 and no longer works. Another repo I found was last updated in January 2020 (meaning it targets the v3 API), describes itself as a “barebones tool”, and requires manual editing of the Python file to download a given docket ID’s comments. So, since there was no pre-existing codebase targeting the v4 API, I built my own.
Getting started quickly with the command-line
The simplest way to get started with this code is to use the command-line. Either clone the entire repo or download comments_downloader.py. It uses Python 3; you’ll also need the pandas library (if you don’t already have it, run pip install pandas, or conda install pandas if you’ve got Anaconda or miniconda installed). The command-line approach allows you to download all of the comments for a given document (specified by documentId) or docket (across all its documents and specified by docketId). In addition to the ID, you’ll need to specify your API key, which you can sign up for on the Regulations.gov documentation page. Note: all instances of DEMO_KEY in this document should be replaced with your API key. The comments will then be downloaded into a CSV named in the format YOUR-ID-HERE.csv in the current directory. For example:
# download all comments for docket FDA-2021-N-0270 (across all its documents)
python comments_downloader.py --key DEMO_KEY --docket FDA-2021-N-0270
Downloading comments for docket ID FDA-2021-N-0270...
2021-07-18 16:26:30: Getting documents associated with docket FDA-2021-N-0270...
Found 1 documents...
2021-07-18 16:26:31: Writing 1 records to document_headers_162630.csv...Done
2021-07-18 16:26:31: Removing any duplicates in the CSV...
2021-07-18 16:26:31: Done. Removed 0 duplicate rows from document_headers_162630.csv.
2021-07-18 16:26:31: Finished: approximately 1 documents collected
Done----------------
******************************
2021-07-18 16:26:31: Getting comments for document FDA-2021-N-0270-0001...
2021-07-18 16:26:31: Getting objectId for document FDA-2021-N-0270-0001...Got it (0900006484a930da)
2021-07-18 16:26:31: Getting comment headers associated with document FDA-2021-N-0270-0001...
Found 188 comments...
2021-07-18 16:26:31: Writing 188 records to comment_headers_162631.csv...Done
2021-07-18 16:26:31: Removing any duplicates in the CSV...
2021-07-18 16:26:32: Done. Removed 0 duplicate rows from comment_headers_162631.csv.
2021-07-18 16:26:32: Finished: approximately 188 comments collected
Done getting comment IDs----------------
2021-07-18 16:26:32: Getting comments associated with document FDA-2021-N-0270-0001...
2021-07-18 16:26:32: Gathering details for 188 comments...
2021-07-18 16:27:03: Writing 188 records to FDA-2021-N-0270.csv...Done
2021-07-18 16:27:03: Finished: 188 comments collected
Done getting all 188 comments for document FDA-2021-N-0270-0001----------------
DONE retrieving all 188 comments from 1 document(s) for docket FDA-2021-N-0270----------------
Similarly, to download all comments on one document, you would specify --document at the command-line and the document ID (i.e., the one you see in the URL):
# download all comments for document FDA-2009-N-0501-0012
python comments_downloader.py --key DEMO_KEY --document FDA-2009-N-0501-0012
Downloading comments for document ID FDA-2009-N-0501-0012...
2021-07-20 20:11:09: Getting objectId for document FDA-2009-N-0501-0012...Got it (09000064847f0822)
2021-07-20 20:11:09: Getting comment headers associated with document FDA-2009-N-0501-0012...
Found 10 comments...
2021-07-20 20:11:10: Writing 10 records to comment_headers_201109.csv...Done
2021-07-20 20:11:10: Removing any duplicates in the CSV...
2021-07-20 20:11:10: Done. Removed 0 duplicate rows from comment_headers_201109.csv.
2021-07-20 20:11:10: Finished: approximately 10 comments collected
Done getting comment IDs----------------
2021-07-20 20:11:10: Getting comments associated with document FDA-2009-N-0501-0012...
2021-07-20 20:11:10: Gathering details for 10 comments...
2021-07-20 20:11:12: Writing 10 records to FDA-2009-N-0501-0012.csv...Done
2021-07-20 20:11:12: Finished: 10 comments collected
Done getting all 10 comments for document FDA-2009-N-0501-0012----------------
Done getting all 10 comments for document FDA-2009-N-0501-0012----------------
One important note: this code does not download attachments (PDFs, Word docs, etc.). However, I added the column attachmentLinks to the output which contains a pipe-separated (|) list of URL(s) for any attachments to a given comment. Given that almost 30% of comments on a given document are “attached” comments, where the text in the body of the comment is something akin to “see attached comment”, this is a significant amount of information, so using the URLs in this column may be necessary for some projects.
It is worth noting that both of the above examples return a small number of comments. If the docket or document you query has over 1,000 comments, you will hit your API key’s rate limit and will have to wait up to an hour for your rate limit to reset. The code will automatically handle this for you, waiting and checking back in every 20 minutes to see if you have been given another 1,000 requests. It is possible to contact the Helpdesk to get up to 2,000 requests per hour, and up to two keys per user.
The command-line is probably all that’s need for 90% of use cases, as people are often only interested in the comments on a particular docket. However, for customized queries, e.g., to download comments for many dockets at once, or to retrieve results in a SQLite database (.db) instead of CSV, you can use Python.
Custom queries with Python
The Jupyter notebook Examples.ipynb in the repository demonstrates how to use comments_downloader.py; it is a good place to get more examples. Note that the pandas library is required to use this code.
The first step in using the code is to import it and create a new instance of the CommentsDownloader class (replace DEMO_KEY with the API key you got at https://open.gsa.gov/api/regulationsgov/#getting-started:
from comments_downloader import CommentsDownloader
downloader = CommentsDownloader(api_key="DEMO_KEY")Example 1:
In the first example, we can download our comments into both a SQLite database and a CSV, specifying our own filenames for each (alternatively, you could also export to only SQLite or CSV):
downloader.gather_comments_by_docket("FDA-2021-N-0270", db_filename="my_database.db", csv_filename="my_csv.csv")The results are the same as you would get at the command-line. There are several benefits to using a SQLite database over a CSV: you can run SQL on it (including joins, etc.), you can add constraints, and there are guaranteed to be no issues with characters in the comment strings that may affect CSV imports. (The code does its best to avoid this issue with CSVs: quote characters are double-quoted and line breaks are replaced with a space so that every row in the CSV is one “record”). One other big benefit is you can store the data from dockets, documents, and comments all in one place. For example, when downloading all comments on a given docket, header information about the documents will be stored in the documents_header table, the comment headers will be in the comments_header table, and the details about each comment (including the text of the comment) will be in the comments_detail table. This is in contrast to the command-line output, which will only output the equivalent of the comments_detail table to a CSV. The full database schema is here.
Example 2
To download all of the comments associated with multiple dockets (or documents) the following scaffolding works well (note that if we had specified a CSV filename instead/in addition, all of the dockets’ comments would be contained in a single CSV file):
my_dockets = ["FDA-2009-N-0501", "EERE-2019-BT-STD-0036", "NHTSA-2019-0121"]
for docket_id in my_dockets:
print(f"\n********************************\nSTARTING {docket_id}\n********************************")
downloader.gather_comments_by_docket(docket_id, db_filename="my_database2.db")
print("\nDONE")An aside
It’s worth noting how much stuff is abstracted away in the three non-print lines of code above. Ordinarily there is no way to go directly from docketIds to comments because the available filters in the API only allow filtering comments by document. So, first you would use your docketIds to query for each docket’s documents, using the documents endpoint (instead of dockets in the above use of gather_headers):
for docket_id in docket_ids:
params = {"filter[docketId]": docket_id}
downloader.gather_headers("documents", params, csv_filename="EPA_water_documents.csv")Then you would use the document headers downloaded into EPA_water_documents.csv to query for their associated comments, but you would first need to get each document’s objectId from that file. This is because the API filters comments by a document’s objectId, not its documentId (my guess is because of a data issue in the backend where there are actually multiple documents with the same documentId; I’ve seen weird behavior for some rare documentIds). You would then use these objectIds to get comments, similar to above:
for object_id in object_ids: # taken from EPA_water_documents.csv
params = {"filter[commentOnId]": object_id}
downloader.gather_headers("comments", params, csv_filename="EPA_water_comments_header.csv")Finally, with these comment headers in hand, you could use each commentId in EPA_water_comments_header.csv to gather the full data for each comment by accessing the “Details” endpoint:
# download the comments
comment_ids = downloader.get_ids_from_csv("EPA_water_comments_header.csv", data_type="comments")
downloader.gather_details("comments", comment_ids, csv_filename="EPA_water_comments.csv")Note that if you had used SQLite, rather than four separate CSV files floating around, you’d have a single database with all these data stored in the same place.
Example 3
Finally, a (slightly) more complex example with a custom query: let’s say we want to download all of the comments associated with EPA dockets containing the term “water” and which were posted between 1/1/2017 and 12/31/2020. Our first step is to get the docket headers with a searchTerm of “water” and a lastModifiedDate between 1/1/2017 and 12/31/2020:
# get the comment headers for these criteria
params = {"filter[lastModifiedDate][ge]": "2017-01-01 00:00:00", # API for dockets doesn't have postedDate filter
"filter[lastModifiedDate][le]": "2020-12-31 23:59:59", # also, these times are in Eastern time zone
"filter[agencyId]": "EPA",
"filter[searchTerm]": "water"}
# this will download the headers 250 dockets at a time, and save the headers into a CSV
# (you could also save them into a SQLite database)
downloader.gather_headers("dockets", params, csv_filename="EPA_water_dockets.csv")The above results download 353 records (dockets) into the file EPA_water_dockets.csv. Now all you have to do is:
docket_ids = downloader.get_ids_from_csv("EPA_water_dockets.csv", data_type="dockets")
for docket_id in my_dockets:
print(f"\n********************************\nSTARTING {docket_id}\n********************************")
downloader.gather_comments_by_docket(docket_id, csv_filename="EPA_water_comments.csv")Additional Reading
For more information on Regulations.gov and its API, you can visit the official documentation, or check out the blog posts that I wrote for a project during my master’s. In particular, post 1 has a section on the web interface and examples of comments, and post 2 goes into much greater detail than this post about the API and some observations. In addition, you can check out the documentation for this code.